

Things to know about large language models
Things to know about large language models
Sifting through some of the hype

Recent progress in large language models—general purpose AI models that can generate human language—has been rapid. However, their future trajectory remains unclear. Last week, many expert researchers and tech leaders signed a statement warning about the risk of artificial intelligence:
Mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war.
This post is an attempt to cut through some of the recent hype and discuss some evidence-supported claims to ground the discussion, drawing inspiration from Sam Bowman’s excellent paper on the state of research in large language models. I echo his disclaimer and motivation:
I do not mean for these claims to be normative in any significant way. Rather, this work is motivated by the recognition that deciding what we should do in light of this disruptive new technology is a question that is best led—in an informed way—by scholars, advocates, and lawmakers from outside the core technical R&D community.
This post will provide intuition for how large language models work, our current understanding of them, and why their future impact remains unclear.
The primary objective used to train language models is simple but profound.
Understanding how language models are trained can allow us to think about them in a more principled way. Current language models are trained with strict mathematical rules on datasets that humans curate.

Stated simply, the goal of a language model is to predict the next word in a sentence, given the previous words.1 We define a loss function to formalize this goal. This loss depends on the probability the language model assigns to the correct word. Here, correctness is determined by whatever word the original author wrote next, so no additional human annotation is needed.
If the model assigns a low probability to the correct word, it receives a high loss and makes a big update to its internal parameters. On the other hand, if the model assigns a high probability to the correct word, it receives a low loss and makes a smaller update. These parameter updates improve the model’s performance on similar word prediction tasks in the future. Repeating this process of making predictions, receiving a loss, and updating the model parameters across trillions of words, we get the backbone for ChatGPT and other powerful models.
It may seem unintuitive why this simple objective works so well. Predicting the next word in a sentence is a surprisingly hard task. A large language model is being tasked to complete everything from Shakespeare to mathematical proofs to Wikipedia articles about 16th century paintings. LLMs can do this because they have billions of parameters and are trained on enormous amounts of data, as shown in the figure above. The data used to train LLaMa, a popular language model from Meta, far exceeds what any human could read and helps explain why LLMs such as ChatGPT can hold conversations on literature, rap, and the sciences.

Understanding this next word prediction objective also helps clarify why the performance of large language models can be quite sensitive to the choice of initial prompt. Current language models process information in a way fundamentally different from how humans process information, as Andrej Karpathy highlights in his slide above. There is a relatively fixed amount of computation applied to generate each word, which is why eliciting more words via prompts such as “Let’s think step-by-step” generally produces higher-quality outputs. The outputs can still feel magical at times, but less so if we deconstruct the objective and understand the mathematical rules governing the training.
With these ideas in mind, we can now introduce the list of claims from Bowman’s paper:
1. LLMs predictably get more capable with increasing investment, even without targeted innovation.
2. Many important LLM behaviors emerge unpredictably as a byproduct of increasing investment.
3. LLMs often appear to learn and use representations of the outside world.
4. There are no reliable techniques for steering the behavior of LLMs.
5. Experts are not yet able to interpret the inner workings of LLMs.
6. Human performance on a task isn't an upper bound on LLM performance.
7. LLMs need not express the values of their creators nor the values encoded in web text.
8. Brief interactions with LLMs are often misleading.
I highly recommend reading the full paper, which cites evidence for each claim and raises additional points of discussion and limitations.
One surprising property for researchers is that these large language models seem to learn and use representations for the outside world. This also make sense from first principle thinking—rather than memorizing a gigantic table of all the multiplication problems that exist on the Internet, it is more efficient to perform multiplication internally with the model parameters. Likewise, it is easier to learn the rules of chess than it is to memorize giant reams of text describing sequences of chess moves. There are more examples under the third section in Bowman’s paper—one example that has received popular attention shows GPT-4 writing coherent code to generate figures:

It is worth reiterating that language models process information in a fundamentally different way from humans and thus can make very different mistakes. This includes hallucination, where LLMs produce nonsensical or untruthful claims. Current language models can also struggle with tasks that involve planning, such as alphabetizing a list of words.
The simplicity of the training objective can be humbling and relates to AI pioneer Rich Sutton’s famous “Bitter Lesson” essay. The success of language models are not overly reliant on clever human ideas beyond the simple training objective—the key factors to increasing capability now are primarily increasing model size and training data. This has resulted in a paradigm shift in the field of training foundation models which are general and adaptable to new tasks. Indeed, we see the bitter lesson in play as “a foundation model that is slightly adapted for a task greatly outperforms previous models or pipelines of models that were built specifically to perform that one task”. These models also “predictably get more capable with increasing investment, even without targeted innovation” (claim 1) meaning that scaling capability of these models may be as much an engineering endeavor as it is a science.
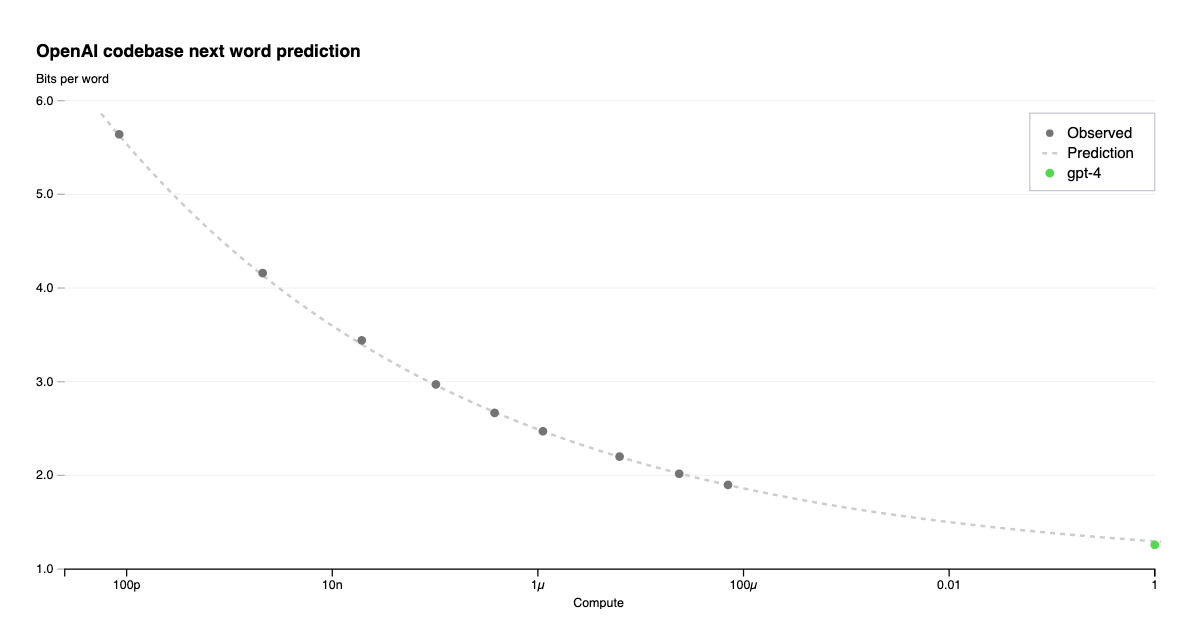
As the figure above shows, models tend to predictably improve with the amount of computational power across many orders of magnitude. As Bowman writes:
Our ability to make this kind of precise prediction is unusual in the history of software and unusual even in the history of modern AI research. It is also a powerful tool for driving investment since it allows R&D teams to propose model-training projects costing many millions of dollars, with reasonable confidence that these projects will succeed at producing economically valuable systems.
While scale tend to increase capability, abilities can also emerge in larger models which are difficult to predict by extrapolating performance on smaller models. For example, the GPT-4 technical report system card highlights challenges such as generated “hate speech, discriminatory language, incitements to violence, or content that is then used to either spread false narratives or to exploit an individual.” These properties of LLMs point to an uncertain future.
There is a lot of uncertainty about what will happen in the future with large models.
The claims from Samuel Bowman’s paper collectively drive home a message of uncertainty; we know that language models are quite capable (and will likely become more capable) but currently have an incomplete understanding of how they work and do not have reliable ways to steer their behavior. Techniques such as prompting or reinforcement learning are used to guide language model behavior, but they are far from perfectly effective. As Bowman describes, scaling model capability affects the problem of steering models in multifaceted ways: LLMs may be more capable of understanding human intention but also develop problems such as sycophancy, where a model answers subjective questions in a way that satisfies a user’s stated beliefs.
There are many concerns about misuse of AI models. Turing Award winners and AI visionaries Geoffrey Hinton and Yoshua Bengio have both publicly voiced concerns. Hinton’s concerns were recently covered in two pieces in the New York Times. There are worries about bias learned from web-scraped training data. There are also concerns about spreading misinformation, job displacement, and weaponization of AI models. The recent statement signed by many luminaries focuses on existential risk, which is a subject of much debate. Bengio recently wrote a detailed post describing how a rogue AI that “could behave in ways that would be catastrophically harmful to a large fraction of humans” may emerge. Kyunghyun Cho, a prominent NYU professor, voiced concern about hero narratives and the hype surrounding existential risk.
There has been intense debate on the relative importance of various risks. Part of the reason is due to the large amounts of uncertainty—no one has made a compelling case for what will happen if we continue on the current trajectory. Due to varying prognostics on how advanced artificial intelligence will look, scientists can have radically different views on what to prioritize.
A scientist who believes that we will be able to align advanced systems with human goals can more easily focus on the boons of advanced AI e.g. faster progress on solving science problems with sophisticated AI assistants. Someone who believes that there is a serious chance misaligned AI creates an existential threat will understandably call for a slow-down or pause in development. Others are justifiably concerned about existing problems created by AI, such as amplification of bias or polarization over uncertain future risks.
I think it is challenging to make concrete predictions on what will happen in the next ten years (or even five years). Nevertheless, it is prudent to scrutinize the incentive structures we have in place. With the relevant lack of structure now, we have companies racing towards building towards more powerful AI due to the tantalizing potential they offer. The GPT-4 model prompted a multi-billion-dollar investment in the company that built it. Nvidia stock rose 24% this past week in response to demand for the hardware they produce to train large models. As Bowman writes, companies are “justifiably confident that they’ll get a variety of economically valuable new capabilities, but they can make few confident predictions about what those capabilities will be or what preparations they’ll need to make to be able to deploy them responsibly.”
Designing incentives that reduce the likelihood that these companies or governments cut corners on safety will improve the odds of these models being broadly beneficial. Currently, there are more incentives and funding to make AIs more capable than there are to prevent and mitigate harms.2 Redistribution of effort from capabilities research to either AI existential safety or ongoing harms would benefit both. Similarly, the effects of job displacement may be reduced if we are proactive in designing policies that facilitate a transition to a world with highly capable AI. Policies are currently being developed in the EU, US, and Canada. Grounding the discourse in evidence will allow for more fruitful discussions and policies.
This could include the previous sentence as well. More generally, we have a maximum context length of words the model can see.